Category Archives: Python
Houdini PLY Exporter
Houdini fileSOP uses gply external command to convert a [b]geo geometry to ply (in Houdini bin). Partly due to PLY’s flexibility, the output isn’t compatible with the PLY reader in Point Cloud Library (PCL), and possibly other common PLY readers. The PLY_exporter I wrote today is an alternative in a Python SOP node. The file header is in a simple heredoc variable in the script so users can easily customize it to exactly how their input software requires.
It’s bare-bones so it assumes P[xyz] and N[xyz] point attributes. Primitives should behave the same as gply. For my raytracer application, I transfer primitive normals to point normals, delete primitives (faces), then export the points & normals. Actually normals is not necessary since the app can estimate normals. In the figure notice most apps don’t use Pw (weight) for polygon/point data, but seems there’s no way to stop Houdini from outputting Pw.
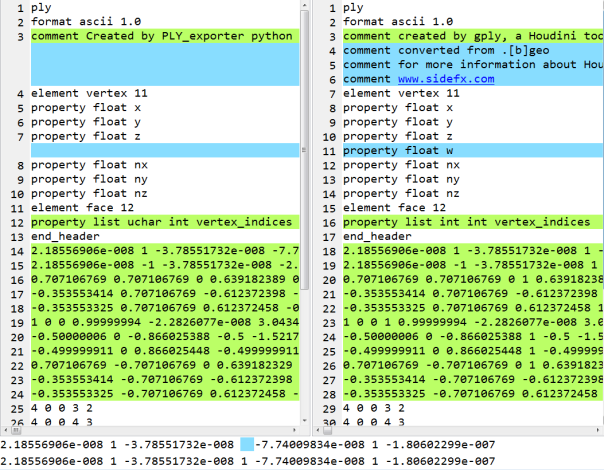
Left: PLY_exporter. Right: gply
Simple GUI
Edit: Apologies to my two commenters (stuck in spam mod) looking for this script, as after the blog was forgotten for five years, most web & local files got lost. Fortunately I found a single text backup, and cleaned up the code as a simpler Python node that functions like the fileSOP. Simply replace your write path in the field (or file dialog), and turn off the bypass flag to write ascii ply files. New version allows exporting whenever the graph cooks, and works with sequences like “file_$F.ply”.
Google drive link: Download PLY_exporter in a sample hip (Houdini 15)
Or if you’re fine editing python, get the script here, and replace “pathStr” with your own path, or replace ‘w’ with ‘wb’ if you need binary file output (as Usama asked).
Enjoy!
Tutorial: SWIG Python Setup
Reviewing C/C++ was somewhat fun. Though more restrictive than Python, macros and classes are delightful. Only when I do STL will I need quick references, otherwise most basic C++/STL is simple. Python seemed to take much longer to learn, probably just more constructs/numpy.
C++ fits performance needs, and more standard OpenCL code. But I like developing in Python. So some options interfacing Python and C (and related optimizing sw) include: Elmer, swig, Shed Skin, unladen swallow, psyco, pyrex.
SWIG documentations weren’t uniform and some outdated parts differed from example files, but the code bits and comments were very helpful. I spent more time finding where’s the install help then actually installing and using C functions.
Extract brebuilt 32bit swigwin-2.0.0 (no install): http://www.swig.org/download.html
Set system ENV variables (this python is XX=26):
PYTHON_INCLUDE: C:\dev\PythonXX\include (has python.h)
PYTHON_LIB: C:\dev\PythonXX\libs (has pythonXX.lib)
OpenCL class & memory
Since I’ve been hitting the speed bottleneck for Radix a few days now, I don’t expect radix to improve. Organized openCL scrap into a simple class that includes rcl.init(…) & rcl.run(). Setups all the CL details and runs an included kernel. Next time I could allow parameters and code as generic inputs.
I’m reluctant rewriting the entire radix in C code, since the massive reliance on dynamic arrays is painful for C. If my school does openCL in C platform instead I’ll get to use C++ wrapper and dynamic data from STLs (hopefully works with CL?). The most gains now would be transform arithmetic-heavy, memory-lite lines into kernels.
float2int_2D(pts) range transform for float to int conversion:
pts 100k, pt_q 1000
t f2i pts_int_2D 17.2699999809 # Wow 1 looped line takes 30% of entire Radix!!
Read the rest of this entry
Radix sort – final python opt
# once q scales up, radix loses. I guess running 2 functions in a loop (2000 function calls) is much heavier.
t_nsmallest 50.5720000267
t_qall 57.7430000305
pts_count 100000
pt_q_count 1000
# 1 function. Very little effect. Oops wrong conjecture.
t_qall 57.6540000439
# Squeezing more ops out the main loop, and packaging them to be parallel friendly.
t_q 0.844000101089
t_q_run 4.35599994659
t_qall 5.20000004768
pts_count 100000
pt_q_count 100
# Parallel friendly turns out to hit the memoryError again. One op had to revert to a slow loop to work. And it’s much slower than looping each q. Seems like heavy memory spaces also affect cpu time.
Read the rest of this entry
Radix root level pruning – Win!
Some major speedup by pruning the root level as well–about 5.5x.
t_radix_sort 0.047, but summing up the detail timings give 0.041. So this 1 function call and leaves return cost 0.006.
I didn’t change the t_radix_setup, hovering in 0.006-0.008.
Compare to python sort time (nsmallest): 0.0439999103546
So after slaying one core function plus small ugly optimizations, radix gets to roughly match nsmallest speed.
>>> execfile(‘classRadix.py’)
mask_digits 4 b 16 pts1.shape (100000, 2) k 1 tree_levels 8 maxabs 21474835
83 mask1 0b1111 W_tl0 134217728 digits_offset [27, 23, 19, 15, 11, 7, 3, 0]
estimated min bucket->digit size 31.25
Read the rest of this entry







